











Decart发布了世界上首个实时的没有时长限制的,还支持任意视频流的扩散视频模型MirageLSD!

不管你输入什么视频流、相机拍摄画面、视频聊天内容、电脑屏幕显示的东西,还是游戏画面。
MirageLSD都能在40毫秒以内,把它转换成你想要的任何风格的世界。

每个人好像都懂点魔法,能随意穿梭在不同的平行时空和幻想世界里。
最让我惊讶的是,不管时长多久,画面始终流畅,风格也没跑偏。

随手拿起桌上的扫帚当麦克风,对着镜头比划,用盒子当混音台,对着镜头比划,无需昂贵设备就能开一场沉浸式直播。

这一切看起来都让人觉得不可思议,AI视频现在已经能像滤镜一样使用了,能实时智能调整画面的风格和内容,还能通过文字提示来随意控制。
01强势出圈,大佬投资
前特斯拉 AI 总监、OpenAI 创始团队成员安德烈・卡帕斯基于这项技术发表了一篇长文:
卡帕斯表示,自己已经成了MirageLSD项目的天使投资人,在他看来,这项技术用途广泛且实力很强。

也许这些都还只是开始,真正能“一出手就惊艳”的应用还没被发掘出来——这个领域值得我们尽情畅想!
02演示案例与体验地址
Decart也展示了一些构想的演示,把各种可能性都展现了出来:
比如在沙漠里滑雪
比如花30分钟写个游戏代码,然后让Mirage来处理画面?👇
Decart在推文中开玩笑说,用Mirage“根据提示词做出《GTA VII》,比《GTA VI》发售还快”。
目前Mirage已经正式上线,与其看着屏幕上的“魔法”,不如自己动手创造“魔法”。
Decart会持续发布模型升级和新功能,包括保持面部形象一致、支持语音控制和精确操控物体等。
同时,平台还会上线一系列新特性——像流媒体支持(能以任意角色进行直播)、游戏集成、视频通话等功能。
03“MirageLSD 技术原理
“魔法”背后的MirageLSD技术原理 MirageLSD主要在视频生成的时长和延迟这两个方面实现了突破。
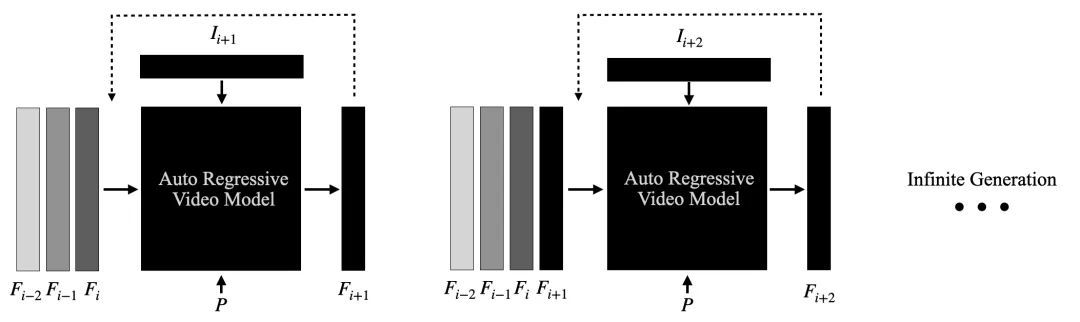
它基于一个定制模型——实时流扩散(Live Stream Diffusion,LSD),这个模型能一帧一帧地生成画面,还能保持画面在时间上的连贯性。
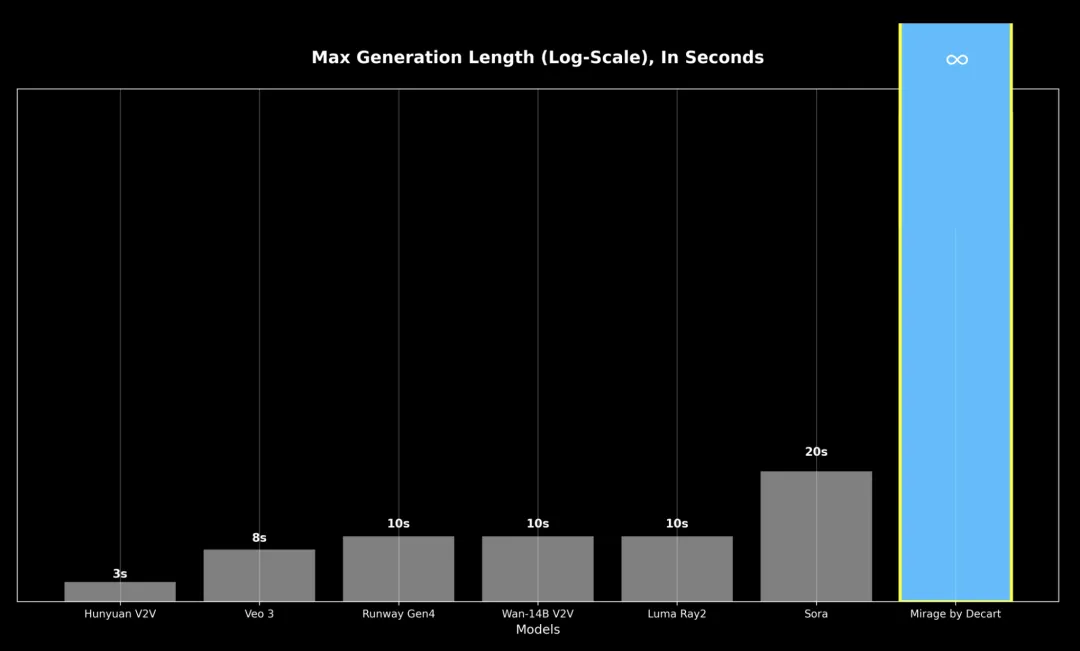
在视频时长上,以前的视频模型生成20到30秒后,就会因为错误越积越多而让质量大打折扣。
在生成延迟上,那些模型往往需要花几分钟处理,才能输出几秒钟的视频。就算是现在最接近实时速度的系统,通常也是把视频分成一块块来生成,这样就难免会有延迟,根本没法用于需要交互的场景。
1.无限长视频生成
2.零延迟视频生成
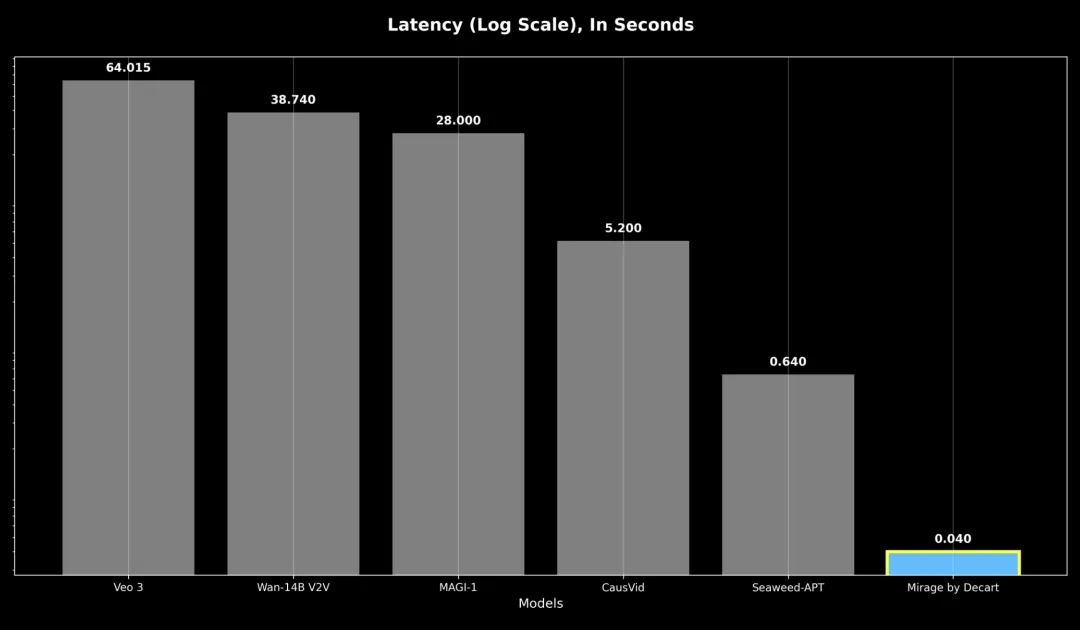
响应性是指最坏情况下的响应延迟,即使是之前的自回归模型响应速度也比 MirageLSD 慢 16 倍以上,导致实时交互无法实现。
-
设计了定制的CUDA核心程序,减少不必要的消耗并提高处理效率; -
用简化模型结构和精简参数的技术,降低每帧需要的计算量; -
优化模型结构,让它和GPU硬件更匹配,从而发挥最大效率。
3.扩散模型与LSD


4.技术缺陷与改进方向

相关导航
















